CBOR vs. JSON vs. libnvpair
My blahg uses nvlists for logging extra information about its operation. Historically, it used Sun libnvpair. That is, it used its data structures as well as the XDR encoding to serialize the data to disk.
A few months ago, I decided to replace libnvpair with my own nvlist implementation—one that was more flexible and better integrated with my code. (It is still a bit of a work-in-progress, but it is looking good.) The code conversion went smoothly, and since then all the new information was logged in JSON.
Last night, I decided to convert a bunch of the previously accumulated libnvpair data files into the new JSON-based format. After whipping up a quick conversion program, I ran it on the data. The result surprised me—the JSON version was about 55% of the size of the libnvpair encoded input!
This piqued my interest. I re-ran the conversion but with CBOR (RFC 7049) as the output format. The result was even better with the output being 45% of libnvpair’s encoding.
This made me realize just how inefficient libnvpair is when serialized. At least part of it is because XDR (the way libnvpair serializes data) uses a lot of padding, while both JSON and CBOR use a more compact encoding for many data types (e.g., an unsigned number in CBOR uses 1 byte for the type and 0, 1, 2, 4, or 8 additional bytes based on its magnitude, while libnvpair always encodes a uint64_t as 8 bytes plus 4 bytes for the type).
Since CBOR is 79% of JSON’s size (and significantly less underspecified compared to the minefield that is JSON), I am hoping to convert everything that makes sense to CBOR. (CBOR being a binary format makes it harder for people to hand-edit it. If hand-editing is desirable, then it makes sense to stick with JSON or other text-based formats.)
The Data & Playing with Compression
The blahg-generated dataset that I converted consisted of 230866 files, each containing an nvlist. The following byte counts are a simple concatenation of the files. (A more complicated format like tar would add a significant enough overhead to make the encoding efficiency comparison flawed.)
| Format | Size | % of nvpair |
| nvpair | 471 MB | 100% |
| JSON | 257 MB | 54.6% |
| CBOR | 203 MB | 45.1% |
I also took each of the concatenated files and compressed it with gzip, bzip2, and xz. In each case, I used the most aggressive compression by using -9. The percentages in parentheses are comparing the compressed size to the same format’s uncompressed size. The results:
| Format | Uncomp. | gzip | bzip2 | xz |
| nvpair | 471 MB | 37.4 MB (7.9%) | 21.0 MB (4.5%) | 15.8 MB (3.3%) |
| JSON | 257 MB | 28.7 MB (11.1%) | 17.9 MB (7.0%) | 14.5 MB (5.6%) |
| CBOR | 203 MB | 26.8 MB (13.2%) | 16.9 MB (8.3%) | 13.7 MB (6.7%) |
(The compression ratios are likely artificially better than normal since each of the 230k files has the same nvlist keys.)
Since tables like this are hard to digest, I turned the same data into a graph:
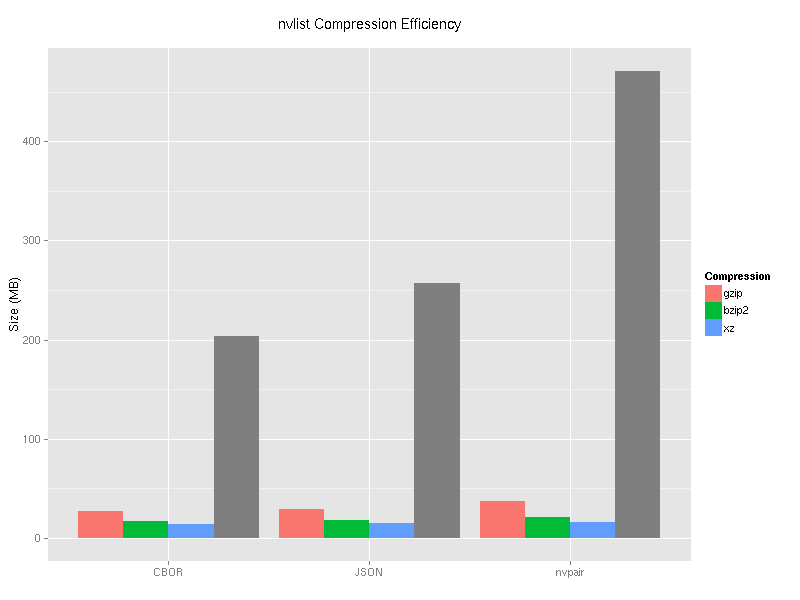
CBOR does very well uncompressed. Even after compressing it with a general purpose compression algorithm, it outperforms JSON with the same algorithm by about 5%.
I look forward to using CBOR everywhere I can.